As I’ve gotten more involved in various open source projects and helping out newbies, I’ve started to realize that many
frameworks rely on a .env file to hold configuration. However, as soon as a developer moves to a framework or language where this is not the case, they get very confused.
Author: withinboredom
-
Your dot-env file doesn’t do anything
-
The Five Critical Roles of Your Team
Long ago, my brother and I shared a room, and we’d stay up late into the night, talking until sleep finally won. One night, we got on the topic of friend groups — how every group we’d ever been part of seemed to include the same types of people. Certain roles just kept showing up, no matter where we lived or who we hung out with.
(more…) -
ChatGPT: A social engineer’s dream
Last night I discovered a new feature in ChatGPT’s app. My wife and I were chilling in a hotel room and I was bored before going to sleep. This feature is called “Deep Research” and it may have been there awhile, or not. I usually just use ChatGPT to answer questions and run some ideas through it every now and then. But when I saw it, I wondered what would happen if I just asked:
(more…) -

How I win without playing to win
My goal isn’t to win. It’s to remove the option for failure.
(more…) -
Yes, another test
I’m so sorry…
-

This is another test
Sorry for the noise, but emails, social links, and the WordPress reader should be working again… 😉
Stay tuned for the magic.
-
This is a test, and only a test
I’ve moved to a headless CMS, and this is a test to make sure everything still works.
Nothing to see here… except emails are probably broken.
-

So, I heard you don’t like pets? Why do you have them?
In the ever-evolving world of DevOps and cloud infrastructure, there’s a mantra you’ve probably heard: “Treat your servers like cattle, not pets.” The idea is straightforward—design systems where individual servers aren’t special but interchangeable parts of a larger herd. Yet despite this wisdom, many of us are guilty of pampering our Kubernetes clusters as if they’re our beloved household pets. So, what’s going on here?
The Philosophy Behind “Cattle, Not Pets”
Before diving into the Kubernetes conundrum, let’s revisit the philosophy. In traditional IT environments, servers were meticulously maintained—named, configured, and nurtured over time. They were pets. If a server went down, it was a big deal.
Enter the “cattle” approach. In large-scale, cloud-native environments, servers are meant to be disposable. If one goes down, you replace it without a second thought. Automation and orchestration tools make this possible, ensuring that workloads continue seamlessly.
Kubernetes Clusters as Pets
When Kubernetes burst onto the scene, it embodied the cattle philosophy. It allowed for the deployment of applications in a way that abstracts away the underlying infrastructure. Pods come and go, deployments scale up and down, and everything is orchestrated to handle failure gracefully.
However, a funny thing happened on the way to the ranch—we started treating our clusters like pets. Instead of spinning up new clusters when changes were needed, we began to:
- Customize clusters extensively, making each one unique.
- Perform in-place upgrades, risking downtime and inconsistencies.
- Hold onto clusters indefinitely, fearing the loss of the intricate configurations we’ve applied over time.
It’s as if we’ve adopted a herd of cattle but decided to give each herd a name and a fancy collar.
The Case for Disposable Clusters
Why should we consider treating clusters as disposable? Here are some compelling reasons:
1. Simplified Upgrades and Changes
Spinning up a new cluster with the desired configuration eliminates the risks associated with in-place upgrades. You can test the new cluster thoroughly before shifting traffic, ensuring a smoother transition.
2. Enhanced Security
Starting fresh allows you to incorporate the latest security best practices and patches without the baggage of legacy configurations that might expose vulnerabilities.
3. Disaster Recovery
In the event of a catastrophic failure, having the ability to quickly deploy a new cluster minimizes downtime and impact on your services.
The Stateless vs. Stateful Dilemma
One of the original design principles of Kubernetes was to handle stateless workloads. Stateless applications are easier to scale and replace because they don’t store data that needs to persist between sessions.
However, as Kubernetes matured, support for stateful workloads improved. StatefulSets and persistent volumes became standard features, encouraging users to run databases and other stateful applications within the cluster.
While convenient, this shift has tethered us to our clusters. After all, you can’t just delete a cluster holding critical data without significant planning and migration.
A Possible Solution: Separate Clusters
Consider maintaining separate clusters:
- Stateless Cluster (Cattle): For applications that don’t maintain state, allowing you to rebuild and replace the cluster at will.
- Stateful Cluster (Pets): Dedicated to stateful workloads that require careful handling and aren’t as easily disposable.
By segmenting your workloads, you can apply the appropriate management strategies to each, embracing the cattle philosophy where it makes the most sense.
Embracing the Cattle Mindset
Shifting back to treating clusters as cattle involves:
- Automation: Use tools like Terraform or Kubernetes operators to automate cluster creation and management.
- Standardization: Develop standardized configurations that can be applied uniformly.
- Immutable Infrastructure: Instead of modifying existing clusters, deploy new ones with the changes baked in.
- Blue-Green Deployments: Route traffic between old and new clusters seamlessly, reducing downtime and risk.
Conclusion
The essence of DevOps and modern cloud infrastructure is agility and resilience. By clinging to our Kubernetes clusters as if they’re irreplaceable pets, we’re hindering our ability to adapt and scale. It’s time to return to the roots of the cattle philosophy.
So, the next time you’re contemplating an in-place upgrade or heavily customizing your cluster, ask yourself: Am I nurturing a pet or managing cattle?
-

Optimizing CGO handles
I work on FrankenPHP quite a bit, which is a PHP SAPI written in Go. For the uninitiated, PHP is written in C, so FrankenPHP uses cgo to interface with PHP. This also means that it uses Handles.
Just to give you a bit of a background on Handles and what they are used for: in cgo, you can’t pass pointers back and forth between C and Go. This is because the memory locations are likely to change during runtime. So, Go provides “Handles” that are a map between a number and a Go interface. Thus, if you want to pass something to C, then when it gets passed back to Go, we can look up that handle using the number and get the Go value.
In essence, this works “good enough” for most applications. The only issue is that it uses a
sync.Mapunder the hood. This means that if we receive 1,000 requests at exactly the same time, we can only process them one at a time. Granted, the current implementation ofsync.Mapis quite fast… so, can we improve it?First, let’s get an idea of how fast it currently is by performing a benchmark. There is only one problem with Go’s current benchmarks: they don’t really show concurrent performance.
Let me illustrate. Here’s the “default” output of the current Handle benchmarks:
BenchmarkHandle BenchmarkHandle/non-concurrent BenchmarkHandle/non-concurrent-16 2665556 448.9 ns/op BenchmarkHandle/concurrent BenchmarkHandle/concurrent-16 2076867 562.3 ns/op
This doesn’t show us anything about the scale of the problem nor what we are solving for. So, I’m going to update the benchmark code a bit to show what is happening:
func formatNum(n int) string { // add commas to separate thousands s := fmt.Sprint(n) if n < 0 { return "-" + formatNum(-n) } if len(s) <= 3 { return s } return formatNum(n/1000) + "," + s[len(s)-3:] } func BenchmarkHandle(b *testing.B) { b.Run("non-concurrent", func(b *testing.B) { for i := 0; i < b.N; i++ { h := NewHandle(i) _ = h.Value() h.Delete() } }) b.Run("concurrent", func(b *testing.B) { start := time.Now() b.RunParallel(func(pb *testing.PB) { var v int for pb.Next() { h := NewHandle(v) _ = h.Value() h.Delete() } }) fmt.Printf("Time: %fs\tTime Each: %dns\tNumber of handles: %s\n", time.Since(start).Seconds(), time.Since(start).Nanoseconds()/int64(b.N), formatNum(b.N)) }) }Now, let us see the output!
goos: linux goarch: amd64 pkg: runtime/cgo cpu: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz BenchmarkHandle BenchmarkHandle/non-concurrent BenchmarkHandle/non-concurrent-16 2618832 459.4 ns/op BenchmarkHandle/concurrent Time: 0.000045s Time Each: 44873ns Number of handles: 1 Time: 0.000063s Time Each: 634ns Number of handles: 100 Time: 0.006349s Time Each: 634ns Number of handles: 10,000 Time: 0.561490s Time Each: 561ns Number of handles: 1,000,000 Time: 1.210851s Time Each: 566ns Number of handles: 2,137,053 BenchmarkHandle/concurrent-16 2137053 566.6 ns/op
Here we can see what is going on under the hood. The benchmark tool actually runs several benchmarks increasing the number of iterations and estimates how many it can do in about 1 second.
Now, we can kind of see our problem: we hit a ceiling on how fast we can create handles. Getting 100 thousand requests at once (not uncommon in a load test) means a minimum latency of ~6 milliseconds for the last request.
How could we implement this in a lock-free way, without using mutexes (or at least, keeping them to a minimum)?
I went for a walk and thought about it. The best I could come up with was some clever usages of slices and partitions. Then I implemented it. (you can see that implementation here, but I’m not going to talk about it)
Once I submitted that patch to Go, it was immediately “held” since it introduced a new API. Thus, I went back to the drawing board to figure out how to implement it without changing the API.
Essentially, it boils down to thinking about how we can cleverly use slices and trade some memory for speed. I started with a basic slice of atomic pointers (
[]*atomic.Pointer[slot]). Now, for those who don’t know about Atomics in Go, we have to use the same type of all things in the atomic. An Atomic can only holdnilinitially, after that, it must hold the same value. So, I needed to create a new type to hold the values: “slots.”// slot represents a slot in the handles slice for concurrent access. type slot struct { value any }But we still need some way to indicate that the value is empty, and it needs to be fast. Thus we will create a “nil slot” that can be easily checked for equality (we can just look at the address).
And finally, we need to atomically be able to grow the slice of slots and keep track of the size atomically as well. Altogether, this results in the following data structures:
// slot represents a slot in the handles slice for concurrent access. type slot struct { value any } var ( handles []*atomic.Pointer[slot] releasedIdx sync.Pool nilSlot = &slot{} growLock sync.RWMutex handLen atomic.Uint64 ) func init() { handles = make([]*atomic.Pointer[slot], 0) handLen = atomic.Uint64{} releasedIdx.New = func() interface{} { return nil } growLock = sync.RWMutex{} }Oh, and we also need a “free-list” to keep track of the freed indices for reuse. We’ll use a
sync.Poolwhich keeps a thread-local list and falls back to a global one if necessary. It is very fast!Creating a Handle
Now that we have all the parts necessary to store our handles, we can go about creating a new handle. Here’s the basic algorithm:
- Set the current handle integer to 1
- Create a
slotfor the data - for ever:
- Check the
sync.Poolfor a released handle- if there is one, set the current handle to it
- See if the current handle is larger than the slice length, if so, grow it
- Try a compare and swap for
nilon the current handle- if it fails, increase the current handle by one
- if it succeeds, we have our handle
- goto 3
For the smart people out there, you may notice this is
O(n)in the worst case and should be “slower” thansync.Mapsince, according to ChatGPT, it should beO(1)to store in the map.However, we are not trying to be “faster,” but lock-free.
The actual implementation looks like this:
func NewHandle(v any) Handle { var h uint64 = 1 s := &slot{value: v} for { if released := releasedIdx.Get(); released != nil { h = released.(uint64) } if h > handLen.Load() { growLock.Lock() handles = append(handles, &atomic.Pointer[slot]{}) handLen.Store(uint64(len(handles))) growLock.Unlock() } growLock.RLock() if handles[h-1].CompareAndSwap(nilSlot, s) { growLock.RUnlock() return Handle(h) } else if handles[h-1].CompareAndSwap(nil, s) { growLock.RUnlock() return Handle(h) } else { h++ } growLock.RUnlock() } }Retrieving a value is
O(1), however:func (h Handle) Value() any { growLock.RLock() defer growLock.RUnlock() if h > Handle(len(handles)) { panic("runtime/cgo: misuse of an invalid Handle") } v := handles[h-1].Load() if v == nil || v == nilSlot { panic("runtime/cgo: misuse of an released Handle") } return v.value }As is deleting:
func (h Handle) Delete() { growLock.RLock() defer growLock.RUnlock() if h == 0 { panic("runtime/cgo: misuse of an zero Handle") } if h > Handle(len(handles)) { panic("runtime/cgo: misuse of an invalid Handle") } if v := handles[h-1].Swap(nilSlot); v == nil || v == nilSlot { panic("runtime/cgo: misuse of an released Handle") } releasedIdx.Put(uint64(h)) }When we put it all together, we can run our benchmarks:
goos: linux goarch: amd64 pkg: runtime/cgo cpu: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz BenchmarkHandle BenchmarkHandle/non-concurrent BenchmarkHandle/non-concurrent-16 11961500 99.17 ns/op BenchmarkHandle/concurrent Time: 0.000016s Time Each: 15950ns Number of handles: 1 Time: 0.000027s Time Each: 272ns Number of handles: 100 Time: 0.001407s Time Each: 140ns Number of handles: 10,000 Time: 0.103819s Time Each: 103ns Number of handles: 1,000,000 Time: 1.129587s Time Each: 97ns Number of handles: 11,552,226 BenchmarkHandle/concurrent-16 11552226 97.78 ns/op
Now, even if we got one million requests at the same time, our latency would only be about 10 milliseconds. Previously, just from handles, our max requests-per-second were ~1.7 million. Now, it is ~10.2 million.
This is a huge speed-up for such a micro-optimization… but what is the actual performance gain in FrankenPHP and what is the “worst-case” of
O(n)actually look like?goos: linux goarch: amd64 pkg: runtime/cgo cpu: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz BenchmarkHandle BenchmarkHandle/non-concurrent BenchmarkHandle/non-concurrent-16 11620329 99.21 ns/op BenchmarkHandle/concurrent Time: 0.000020s Time Each: 20429ns Number of handles: 1 Time: 0.000019s Time Each: 193ns Number of handles: 100 Time: 0.002410s Time Each: 240ns Number of handles: 10,000 Time: 0.248238s Time Each: 248ns Number of handles: 1,000,000 Time: 1.216321s Time Each: 251ns Number of handles: 4,833,445 BenchmarkHandle/concurrent-16 4833445 251.7 ns/op
In the worst case (ignoring our “free-list”) we are still handily faster than the original implementation (about twice as fast).
For those of you who like graphs, here it is:
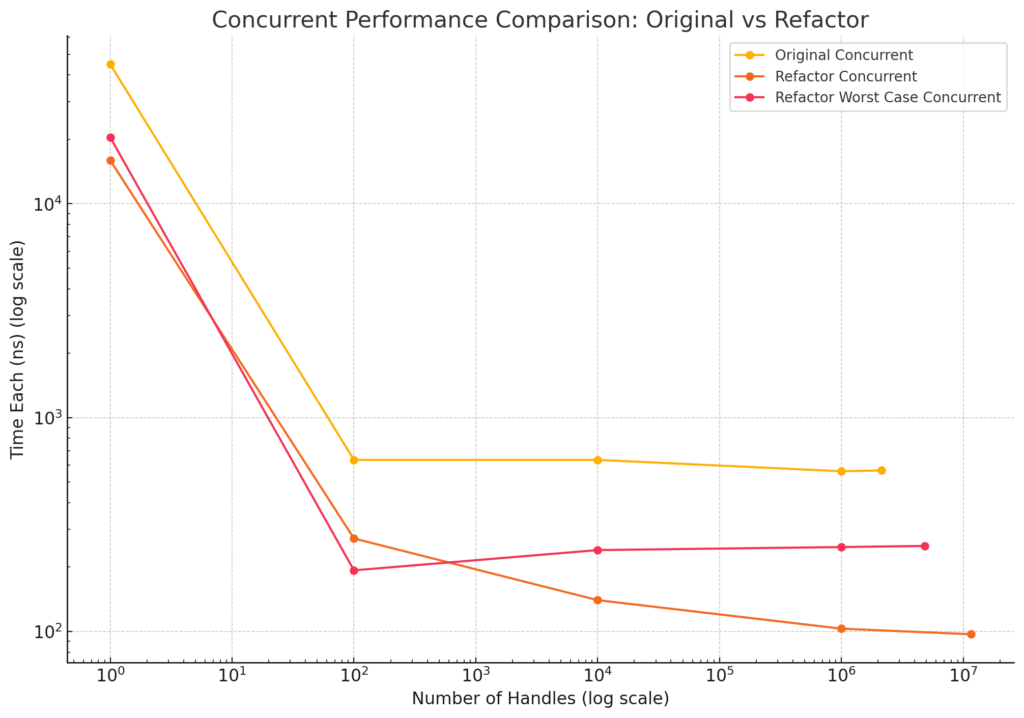
For FrankenPHP, it results in a 1-5% increase in requests-per-second. So, while this does measurably improve the performance of FrankenPHP, it doesn’t equate to the 5x improvement we’d expect; which means it is time to go hunting for more improvements in Go.
I’ve submitted a CL to Go with these improvements: https://go-review.googlesource.com/c/go/+/600875 but I have no idea if they will ever review it or consider it. From Go’s perspective (and most developers) this isn’t usually something on a hot-path that would benefit from such a micro-optimization. It’s only when handles are being created on a hot-path (such as in FrankenPHP’s case) that any performance gains can be realized.
-
Classifying Pull Requests: Enhancing Code Review Effectiveness
In today’s rapidly evolving software development landscape, increasingly complex systems present new challenges in code reviews. As projects grow in size and scope, efficient code review processes become essential to maintain code quality and developer productivity. By understanding and categorizing pull requests (PRs), developers can streamline reviews, improve code quality, and foster better collaboration. Research supports the idea that clear classification of PRs can lead to more efficient and productive code reviews.1 2 In this essay, we will explore the classification of pull requests into three fundamental categories—Features, Refactors, and Updates—and discuss their impact on the code review process.
Class I: Features
Features represent the core advancements and additions to a codebase, introducing new functionalities or modifying existing ones. These changes are crucial for software evolution and enhancing user experiences. Class I PRs are characterized by:
- Predominantly line additions or deletions
- Modifications to public interfaces such as arguments, public methods, fields, or literal interfaces.
- Updates or additions to tests to ensure the new or altered functionality works as intended.
Features are the driving force behind software development, enabling products to meet new requirements and improve user satisfaction.
Example
Imagine a typical Feature PR involving the addition of a new API endpoint. This PR would include new code for the endpoint, updates to the interface to accommodate the new functionality, and tests to ensure the endpoint works correctly.
Class II: Refactors
Refactors are internal modifications aimed at improving code readability, maintainability, or performance without altering its external behavior. These changes make the codebase cleaner and more efficient. Class II PRs typically include:
- A mix of additions and deletions, often balancing each other out.
- No changes to public interfaces, ensuring the software’s external behavior remains consistent.
- (Usually) No need for test updates, as the functionality remains unchanged.
Refactors are essential for maintaining a healthy codebase, making it easier for developers to understand and work with the code over time.
Example
A Refactor PR might focus on improving code readability by renaming variables and functions to more meaningful names, reorganizing methods for better logical flow, and removing redundant code. These changes do not alter the functionality but make the code easier to maintain.
Class III: Updates
Updates encompass changes to existing features, which may include bugfixes, performance improvements, or modifications to enhance existing functionality. These changes are observable and typically require updates to tests to confirm that the issue has been resolved or the improvement is effective. Class III PRs are characterized by:
- An almost equal number of additions and deletions.
- Potential changes to public interfaces to implement the necessary improvements.
- Necessary updates to tests to verify the changes.
Updates are crucial for maintaining software reliability and user satisfaction, ensuring that the software performs as expected.
Example
Consider an Update PR that improves the performance of an existing feature causing delays under specific conditions. This PR would involve code changes to optimize the feature, possibly updates to public interfaces if necessary, and new or updated tests to ensure the improvement is effective.
The ideal pull-request
An ideal PR is focused and belongs to a single primary class of changes. It should be small, manageable, and dedicated to one purpose, whether it’s adding a feature, refactoring code, or updating an existing feature. Such PRs are easier to review, test, and integrate into the codebase, reducing the risk of introducing new issues.
Challenges and mixed-class PRs
While the ideal PR belongs to a single class, mixed-class PRs are common in larger projects. These PRs can be more challenging to review due to their complexity and the cognitive load they impose on reviewers.
Class IV-A: Update-Refactors
These PRs combine updates with refactoring changes. They often face criticism due to the difficulty in distinguishing between update-related changes and refactor-related changes. The lack of tests for the refactoring portion makes the diff hard to follow, complicating the review process.
Why Problematic?
Update-Refactor PRs blend the urgency and importance of updates with the less critical, but still valuable, refactoring tasks. This combination can obscure the main purpose of the PR, making it difficult for reviewers to prioritize their focus. The need to verify both the updates and the refactoring changes can lead to longer review times and increase the likelihood of errors slipping through. Additionally, the cognitive load increases as reviewers must switch contexts between understanding the update and assessing the refactoring efforts.
Class IV-B: Feature-Refactors
Similar to IV-A, these PRs include both new features and refactoring. They can be challenging to review as the introduction of new functionality is intertwined with internal code improvements, making it hard to assess each aspect independently.
Why problematic?
Feature-Refactor PRs can be problematic because they mix strategic, high-level changes with tactical, low-level improvements. This dual focus can dilute the reviewer’s attention, making it harder to ensure that the new feature works correctly and that the refactoring is effective. Reviewers may miss critical interactions between the new feature and the refactored code, leading to potential integration issues or unforeseen bugs.
Class IV-C: Update-Features
These PRs are particularly problematic as they attempt to update existing features while simultaneously adding new features. They are usually large and complex, requiring significant effort to understand the interplay between the updates and the new functionality.
Why problematic?
Update-Feature PRs are the most challenging because they require reviewers to juggle understanding the update, verifying the change, and evaluating the new feature. This combination can lead to confusion, as reviewers may struggle to separate the different types of changes and their impacts. The complexity of these PRs can result in longer review times, higher cognitive load, and a greater chance of introducing new bugs or missing critical issues.
Class V: Balls of Mud
Occasionally, a PR mixes all types of changes together—features, refactors, and updates—resulting in an unwieldy and massive diff. These PRs are the hardest to review, often leading to confusion and potential oversight of important details
Why problematic?
Balls of Mud PRs are essentially a worst-case scenario in code reviews. They present an overwhelming number of changes that can obscure the purpose and rationale behind each modification. Reviewers can become bogged down in the sheer volume of changes, leading to review fatigue and the potential for important issues to be overlooked. The lack of focus in these PRs can also make it difficult to ensure that each change is adequately tested and integrated, increasing the risk of regression bugs and integration problems.
Strategies for managing mixed-class PRs
- Break Down PRs: Whenever possible, break down mixed-class PRs into smaller, focused PRs. This makes each PR easier to review and ensures that changes are more manageable.
- Clear Commit Messages: Use clear and descriptive commit messages to separate concerns within a single PR. This helps reviewers understand the purpose and impact of each change.
- Detailed Documentation: Provide detailed documentation and comments explaining the changes, especially for mixed-class PRs. This aids reviewers in understanding the rationale behind the modifications.
- Multiple Reviewers: Involve multiple reviewers with different expertise areas to handle complex, mixed-class PRs. This can help distribute the cognitive load and ensure a more thorough review.
Classifying pull requests into distinct categories significantly enhances the code review process by improving focus, efficiency, and collaboration, while maintaining high code quality. By aiming for focused, single-class PRs, developers can reduce review times and improve the overall quality of the codebase. However, managing mixed-class PRs remains a challenge that requires careful attention to detail and clear communication among development team members.
written and researched with the help of A.I.
-

Hacking PHP’s WeakMap for Value Object D×
This guide will allow you to use value objects in PHP without a special
$obj->equals()===or==operator to compare two value objects. This guide will also show you how to use a WeakMap to ensure that you don’t
create multiple instances of the same value object and how to hack WeakReferences to do the same when backing
scalar values.The Base Value
Before we get started, we need to figure out what our Value Objects will represent. In this example, we will use time as our value. Our values will be wrapped numbers, but they could also be strings or any other arbitrary value. If you have a specific, predefined set of numbers or strings, this guide isn’t for you; use enums instead. For something like time, a user should be able to say, “Are 5 seconds equal to 5,000 milliseconds?” The answer should be “Yes.” They should be able to do this without using special methods or using the
==operator.Before we write any code, we need to decide on our base value. In this example, we will use milliseconds to keep things simple.
So, let’s dive into some code! Here’s the basic structure of the class:
readonly class Time { private int $milliseconds; public function asSeconds(): float { return $this->milliseconds / 1000; } public function asMilliseconds(): float { return $this->milliseconds; } public function asMinutes(): float { return $this->milliseconds / 60000; } }This class is pretty straightforward. It has a single property,
$milliseconds, and three methods to convert the value to seconds, minutes, and milliseconds. We could add more methods, but this is enough for now.Creation
To create proper value objects for our purposes,
having direct access to the constructor would prevent us from being able to enforce the value’s identity since callingnew Time(5000)andnew Time(5000)would create two different objects, we need to use a factory.readonly class Time { private function __construct(private int $milliseconds) {} public static function fromMilliseconds(int $milliseconds): Time { return new Time($milliseconds); } public static function fromSeconds(float $seconds): Time { return new Time($seconds * 1000); } public static function fromMinutes(float $minutes): Time { return new Time($minutes * 60000); } /* ... */ }Now, we can create a Time object like this:
$time = Time::fromMilliseconds(5000);
However, you’ll notice that
Time::fromSeconds(1) !== Time::fromMilliseconds(1000)The Weak Map
To solve this problem, we can use a WeakMap. A WeakMap is a map with weak references to its keys, meaning that if the key isn’t used anywhere, the WeakMap will remove the key and its value from the map.
What we need to do is something like this:
- See if any Time objects have the same value in the WeakMap.
- If there are, return the existing object.
- If there aren’t, create a new Time object and store it in the WeakMap.
The actual implementation would look more or less like this:
function getValue(int $milliseconds): Time { static $weakmap; $weakmap ??= new WeakMap(); return $weakmap[$millisecondes] ??= Time::fromMilliseconds($milliseconds); }However, you’ll note that you can’t exactly put scalar values in a WeakMap, as they’re not objects. We must be more creative and use an array to get around this. However, if we use an array, we must ensure we behave like a WeakMap. If we’re wrapping regular objects, then the above algorithm is all we need. However, if we’re wrapping scalar objects, we need an array of WeakReferences.
Array of WeakReference
As mentioned earlier, we must use an array of WeakReferences to store our values. So, let’s get started:
- Create a static array that we use to hold our wrapped values.
- Create a WeakReference for each wrapped value we store in the array.
- When we need a wrapped value, we check if the raw value is in the array.
- If it is, we return the wrapped value.
- If it isn’t, we create a new wrapped value from the raw value, store it in the array, and return the wrapped value.
- On destruction, remove the raw value from the array.
Here’s the implementation with comments:
class Time { private static array $map = []; private static function getValue(int $milliseconds): Time { // Attempt to get the value from the array, and if it exists, get the // value from the WeakReference, otherwise, create a new one $realValue = (self::$map[$milliseconds] ?? null)?->get() ?? new self($milliseconds); // Store the value in the array, even if another reference exists self::$map[$milliseconds] = WeakReference::create($realValue); return $realValue; } public function __destruct(){ // The values no longer exist, and we can delete the value from the array unset(self::$map[$this->milliseconds]); } /** ... */ }This implementation is a bit more complex than the WeakMap but still pretty straightforward. We create a new Time object if one doesn’t exist yet; otherwise, return the existing one. Upon destroying the object, we remove it from the array since the WeakReference is about to be empty.
You may notice the odd way the “getting from the array” is structured and that we store it in a
$realValueobject. There are several reasons for this.- This is actually pretty darn fast.
- We have to hold a reference to the created object, or it will be removed from our array before we ever return it.
- Just because we have a
WeakReference, doesn’t mean it holds a value.
Even with this knowledge, you might be tempted to rewrite it like so:
$realValue = self::$map[$milliseconds] ?? WeakReference::create(new self($milliseconds);
However, because there isn’t anything but the
WeakReferenceholding a reference tonew self(), it will immediately be deleted. The provided listing is an efficient way to extract a value if one exists and hold a reference to it in$realValue.Comparisons
Using a consistent base value means relying on regular PHP comparisons without special magic. The way that PHP compares two objects is by inspecting their properties — if they are the same type. Since there is only one property and it is numeric, the following are true:
Time::from(TimeUnit::Seconds, 1) > Time::from(TimeUnit::Milliseconds, 1)
To simply “just work.”
Thus, the only special operators we need are mathematical operators.
Full Listing
Before we get to the full listing, there are few more small improvements:
- We should make the class
final. I’m usually against final classes, but we must do careful manipulations in this case, and a child class may override important behaviors which may cause memory leaks. I’ll do that now. - We can use enums for units to simplify our from/to logic. I’ll go ahead and do this as well.
- I’ve updated my Time Library to use this.
Here’s the full listing:
enum TimeUnit : int { case Milliseconds = 1; case Seconds = 1000; case Minutes = 60000; } final class Time { private static array $map = []; private static function getValue(int $milliseconds): Time { // Attempt to get the value from the array, and if it exists, get the // value from the WeakReference, otherwise, create a new one $realValue = (self::$map[$milliseconds] ?? null)?->get() ?? new self($milliseconds); // Store the value in the array, even if another reference exists self::$map[$milliseconds] = WeakReference::create($realValue); return $realValue; } public function __destruct(){ // The values no longer exist, and we can delete the value from the array unset(self::$map[$this->milliseconds]); } private function __construct(private readonly int $milliseconds) {} public static function from(TimeUnit $unit, float $value): Time { return self::getValue($unit->value * $value); } public function as(TimeUnit $unit): float { return $this->milliseconds / $unit->value; } }With the advent of property hooks in PHP 8.4, it might be simpler to mix the behavior and provide actual hooked properties:
final class Time { private static array $map = []; public float $seconds { get => $this->milliseconds / 1000.0; } public float $minutes { get => $this->seconds / 60.0; } private static function getValue(int $milliseconds): Time { // Attempt to get the value from the array, and if it exists, get the // value from the WeakReference, otherwise, create a new one $realValue = (self::$map[$milliseconds] ?? null)?->get() ?? new self($milliseconds); // Store the value in the array, even if another reference exists self::$map[$milliseconds] = WeakReference::create($realValue); return $realValue; } public function __destruct(){ // The values no longer exist, and we can delete the value from the array unset(self::$map[$this->milliseconds]); } private function __construct(public readonly int $milliseconds) {} public static function from(TimeUnit $unit, float $value): Time { return self::getValue($unit->value * $value); } }Conclusion
I’m really excited to share this approach with you, as it enables some nice benefits when working with value objects. You no longer need special
->equals()assert(Time::fromSeconds(10) === Time::fromMilliseconds(10000))and get the expected result.I hope you find this guide useful and can use it in your projects. If you have any questions or suggestions, please email me or post them in the comments section below.
Playground: https://3v4l.org/dVEOP/rfc#vrfc.property-hooks
-
Algorithms in PHP: Deques (and circular buffers + linked lists)
If you’ve ever tried to use an array as a queue or stack (via
array_pop,array_push,array_unshiftandarray_shift), you may have discovered they are slow, particularly array_unshift which requires shifting the entire array. Here are the limits of the awesome PHP array: prepending. Prepending to an array is a very costly operation in PHP, and there isn’t really any way to get around it, or is there?Queues and Stacks
In computer science, there are two fundamental things for batch processing: queues and stacks. A queue is a first-in-first-out (FIFO) construct, and it works just like a queue at a grocery store. The first person in the line is the first person who gets checked out.
A stack, on the other hand, is a first-in-last-out (FILO) construct. You can imagine this just like a stack of plates. As you “push” plates onto the stack, the first plate you place is the last plate you’ll “pop” off the stack.
Both of these structures are amazing for being able to do any kind of bulk work. However, sometimes you must utilize a sequence as a stack and a queue. For example, if you require storing the last 500 items of something, but want to iterate it in reverse (undo features come to mind here).
The Deque
Enter the deque (pronounced “deck”). Deques are slightly magical in being able to use them like a queue and a stack. Taking items off and on from either end is O(1) while accessing the middle is still O(n). They are usually implemented on top of linked lists or a circular buffer.
A deque is incredibly powerful for “undo” features. You push operations onto the deque and shift items at the bottom once it gets above a specific size, allowing you to easily “undo the last X actions.” So, if you ever see some requirements for a “limited size stack” or “limited size queue,” you’re probably looking to use a deque.
A short disclaimer
Before we get into implementation of a Deque, I feel like a disclaimer is needed. The code shown on these posts shouldn’t be used in production. I’m not doing a lot of error handling, and in some cases, ignoring edge cases altogether. I’m merely trying to illustrate the principles for those cases where you need to implement it yourself. For example, WordPress implements a priority queue similar to the last post to support filters/actions in order to support insertion/deletion while iterating the queue. Beanstalkd uses a custom heap sort to support
Nieve implementation
First, let us look at a very nieve implementation:
<?php namespace Withinboredom\Deque; class Nieve { private array $buffer = []; /** * Append to the end of the array * * @param mixed $value * * @return void */ public function push( mixed $value ): void { array_push($this->buffer, $value); } /** * Get from the end of the array * @return mixed */ public function pop(): mixed { return array_pop($this->buffer); } /** * Get from the beginning of the array * @return mixed */ public function shift(): mixed { return array_shift($this->buffer); } /** * Append to the beginning of the array * * @param mixed $value * * @return void */ public function unshift( mixed $value ): void { array_unshift($this->buffer, $value); } }As you can see, it is pretty simple. You should note that it is also very slow and gets slower as the array gets bigger.
Don’t do this unless you only have a very small list (~100-200 items).
Implementing a circular buffer
We can use a regular array, just like our nieve implementation, but implement a circular buffer. This would make the major cost of our implementation be the overhead of array accesses. To implement a circular buffer, we must understand what a circular buffer is and its requirements.
I’m not going to go into depth on how a regular one works, so I highly recommend pausing here and learning about regular circular buffers. We need a special circular buffer: a double-ended circular buffer.
This works similarly to a regular circular buffer, except we have two cursors: the “head” and the “tail.” These allow us to insert items at “the front” and “the back” while also allowing us to read those items.
To add an item to the head of the buffer:
- Check if the deque is full.
- If we are already at our initial position, move to the end of the array.
- Else decrement the pointer.
- Add the item to the array.
To add an item at the tail of the buffer:
- Check if the deque is full.
- If we are already at the end of the array, move to the beginning of the array.
- Else increment the pointer.
- Add the item to the array.
-
Where is my birthday day?
I was born on a Wednesday, and for some reason, when my birthday falls on a Wednesday, I always consider it a “special” birthday: a Birthday Day.
It’s been a long time since I’ve had a Birthday Day — almost ten years! When I was 12-13 years old, I did some work to discover that my Birthday Day would be every 5-6 years, but apparently, I didn’t do the math for one more cycle!
There are cycles to Birthday Days, depending on which day of the week the leap year is in relation to the day you were born. The cycle goes 11, 6, 5, 6 years, but the mapping looks sorta like this:
For example, if you were born on January 2, 1980, your first cycle is five years and looks something like this:
It’s interesting to note that during these five years, you wouldn’t have a birthday on a Tuesday or Thursday. Then, after five years, you enter a six-year cycle:
Where you don’t have a Sunday birthday, and finally, you enter the 11-year cycle:
This is the current cycle I am in, and most of my family is as well. I’m near the end of it, but my wife is just entering it. I should note that there is another 5-year cycle, and then the cycles repeat.
I’ve provided one that allows you to configure your settings below so you can see which cycle you are on and when your next Birthday Day is.
PS: note that 2100 is NOT a leap year (century years are only leap years when divisible by 400), so the pattern breaks around that time… 😉
-
Building DPHP: Authz and Ownership
Durable PHP is a framework for writing arbitrarily complex code that scales. It’s still under active development, but I thought I’d write a few blog posts about it before I release the documentation on how to use it. Today, I want to talk about Authorization/Authentication and Ownership.
In any software project, there are users. These users interact with resources, usually via CRUD (Create, Read, Update, and Delete). However, Durable PHP has a bit more fine-grained actions:
- Start: creates a new orchestration
- Signal: send an event somewhere, but no return address.
- Call: send an event somewhere with a return address and be notified upon completion
- Read: retrieve snapshots of distant state
- Subscribe: be notified of status changes
- Delete: just what it sounds like
Durable PHP treats everything as a resource, whether it is an activity, entity, or orchestration and every resource must be owned by something or someone. The application developer is responsible for what those entities are and what the permissions are, which can be rather fine-grained.
From there, the are only a few basic rules you need to know:
- A user can own a resource. They have full control over the resource.
- A user can share an owned resource with another user or role.
- A user can share Read/Update/Delete rights to a resource they own.
- A user can only interact with a resource if they have a right to do so.
These rules are important to know because all code you write is operating in the context of the user, enforced by the infrastructure. This prevents a number of security concerns, where even if a user were to inject an ID of something they weren’t supposed to have access to, your code wouldn’t have access to it. This is much more similar to sandboxing that an OS does on a mobile device, where the user who owns the resource has to give you permission to access it.
There is, however, a sudo mode for users of the role
admin. These users are able to access anything, even if they don’t have permission to do so. This allows administrators to perform actions on behalf of other users, for performing customer support or other administrative tasks.One technique I’ve used is to have an entity owned by an administrator. Code that needs to run elevated operations calls the singleton entity and asks for permission. If it’s allowed, it will simply execute the code as an admin, otherwise, request a human admin to check if it is allowed and approve/disapprove it.
For example, in the context of a chat app, an HR person might need to access private chats of a user. If, in the context of my app, they have the appropriate role, I would allow them to access that in the context of an admin; otherwise, I would elevate this to a human as this is either an application bug (the user seeing a button they shouldn’t see) or someone is doing something fishy.
I’m very happy with this authorization system, as it is extremely clean (<120 lines of code) and quite flexible.
-
Building DPHP: Distributed Locks
Durable PHP is a framework for writing arbitrarily complex code that scales. It’s still under active development, but I thought I’d write a few blog posts about it before I release the documentation on how to use it. Today, I want to talk about distributed locking.
In Durable PHP Orchestrations, you can lock Entities (as many as you want) in a single statement. This is ripe for a deadlock, especially if you have an Orchestration taking multiple locks on multiple Singleton Entities. Let’s imagine the following sequence diagram:

If another Orchestration comes along and tries to lock, which one succeeds? How do we prevent a deadlock where neither Orchestration will make progress?
This turns out to be a hard problem with a relatively simple solution by following only a few rules:
- If an Entity has a lock on it, queue all other requests until the lock is released.
- If an Orchestration takes a lock, the order must be deterministic.
- If an Orchestration terminates, it must release all locks.
Further, we must not take a lock in our lock sequence until we receive acknowledgement that we have a lock. This looks something like this:

By following these rather simple rules, we can prevent (most) deadlocks. I don’t believe they are entirely impossible, but I think for most cases, they’ll resolve themselves as long as people ensure there is a timeout on the lock.
I experimented with many different implementations, and I’ll share them here.
Cooperative Entities
One of the first implementations I attempted was through composing lock events addressed to multiple entities and then having the entities cooperate to jointly create a lock. This turned out to effectively having the same behavior that I eventually went with. In fact, it was through observing the behavior and edge cases of this implementation that led me to the result. However, I believe this implementation, had I gone with it, would have been easier to optimize. The current implementation requires 2n messages per lock, where this original implementation could have been optimized to need only n+1 messages. However, I determined the resulting complexity would have simply been too much to easily maintain. It was simply too brittle.
Future Optimizations
Currently, there is infrastructure level locking that simply didn’t exist when I wrote the original code. Now, there are better ways to perform a lock that make more sense. A future optimization could take advantage of this locking mechanism to require only n messages to perform a lock. This would greatly speed up critical code paths that require locking.
-
Building DPHP: Event Sourcing
From the beginning, I knew Event Sourcing would be a big part of Durable PHP, and I learned from several Event Sourced projects I’ve built or worked on over the years. Specifically, I knew what issues any project would have to deal with, and I wanted to create a framework where none of those issues existed.
I’ll go into the gist of Event Sourcing now, but feel free to skip to the next section if you think you know how it works.
Event Sourcing is a paradigm of writing software where the state is computed by replaying events. For example, an inventory item isn’t created out of thin air, like in CRUD; rather, it is “received” into inventory from somewhere else. This “received event” allows us to calculate how many items were added to the inventory by counting those events. To remove items from inventory, we might “sell” them or “trash” them, allowing us to get the current inventory state by simply keeping track with a +1/-1 of items.
Further, we might “project” the current state into a traditional database for faster querying or use in other parts of the software.
There’s far more to this than meets the eye, so I highly suggest reading up on it if you are interested … but this is where we’re going to deviate from “application level” Event Sourcing.
Layers
In Durable PHP, Event Sourcing is done below the application level. You only interact with it tangentially in Entities and a bit more directly in Orchestrations. In other words, Durable PHP is a framework for Event Sourcing in PHP without even having to know that is what you are working with and how it works.
One of the key aspects of Event Sourcing in Durable PHP is the layers. If you’ve worked with traditional software, you’ve probably heard of “application layers,” “persistence layers,” and so forth, responsible for various application lifecycles. In Durable PHP, there are different layers:
- Infrastructure: routing and authorization
- History: aggregation and locking
- Context: linearization and API
- Application: business logic
The two layers that are very often kept as “secret” in any implementation of Event Sourcing are the middle layers: History and Context. In Durable PHP, the History layer keeps track of whether or not we’re replaying events, which events we’re waiting for, and which we’ve already processed. We’re also keeping events queued up for after a lock is released and helpful state for managing distributed locks.
The Context layer provides a projected state to the Application layer so that the application code doesn’t need to know how it works or is stored. As far as the application code is concerned, it works just like any other PHP code.
This alleviates the need for a (no)SQL database entirely since the application state appears to itself as though it is continuously running, even though it is only running when triggered to do so.
Storage
You’ll note that I mentioned that a database isn’t technically needed. The state is stored as blobs that can be loaded on demand and projected to TypeSense (or anything, really) if searching is required.
Since the state is simply a collection of blobs, we can operate optimistically in certain contexts, using “Etags” to catch concurrency issues. We simply throw away the results and restart if another operation beats us to storage. In performance tests, this is much faster (>10x faster) than trying to take a distributed lock and only run one operation at a time. This technique also embraces out-of-order events and leaves figuring out what is going on to the Context layer. A distributed lock is the only way to proceed in some contexts where we expect an external side effect since we need exactly-once semantics.
Even then, we can prevent side-effects for certain types of side-effects until we are sure the state has been committed. The gist of a state-commit looks something like this:
- Try to commit state
- If success: perform side-effects
- If failure: trash and rerun from the stored state
From the outside, this looks like exactly-once semantics, but from the perspective of the code, it may many, many times.
Composable Events
One early optimization I did was to create composable events. There are only a few core events and many composable events. For example, any event may be delayed by wrapping it in a
Delayevent, providing addresses to send responses to, sharing ownership, including a lock request, and more. This greatly increases the expressibility of events while working on the system and allows for greater control when dealing with events in different layers. For example, the Infrastructure layer is concerned with delays and ownership, the History layer is concerned with locks, and the Context layer is concerned with who to send replies to.This, hands down, was one of the best early-game decisions made. I’ve seen plenty of Event Sourced code in my time, and the
Eventobject always eventually ends up being this opaque blob of flags, and dealing with them is a spaghetti monster of if-statements. By using composable events, I ended up with very few if-statements, unwrapping the event one layer at a time.Challenges
One of the biggest challenges when working on this was the interactions between the Context and History layers, such as waiting for multiple events and dealing with out-of-order events. I ended up with what I felt was a pretty elegant solution.
We need to keep track of what we are waiting on and only care about those. Everything else can be ignored until we are waiting on those events. This also means that the event order isn’t related to the order it was received, but instead, the order is the order we expect them and the order we received them (if we expect multiple events). This can probably be optimized at some point, but it is unlikely to be optimized any time soon.
This is super important for replaying code, as we want to be sure that code isn’t considered “replaying” simply because we received an out-of-order event.
Another huge challenge was testing. The hardest part of any application to test is the interface between parts. You can test the contracts, but only end-to-end tests will test whether the contract is fulfilled correctly. Naturally, I didn’t want end-to-end tests with actual events, so I needed to build a custom system to inject events in whatever order I want. Then, verify things as it plays out. It was very tedious but worth it in the end. None of this is required for end users. However, to validate that things work correctly, it is very much required.
Event Sourcing Done Right?
I’m working on a rather fun application using Durable PHP; to find all the edge cases, polish up some of the rough edges, and make it a pleasure to use. Of all the Event Sourcing libraries and shenanigans I’ve ever used, I’m actually really happy with this. There’s still much more tooling to build, but I’m getting there, one weekend at a time.
-
Building DPHP: What is it?
I’m fascinated by event-driven systems. In these systems, everything happens for a reason, which is just as important as its effect on the system. In my perfect universe, everything is built to be event-driven… but very few things deserve the complexity of creating such a thing.
Durable PHP started as a solution that allowed arbitrarily complex software to be built quickly and just as fast to write tests for. I wanted it to force developers to write testable code while making the testing experience effortless.
To do that, I took inspiration from some great libraries and frameworks I really enjoyed working with over the years: Akka, Durable Functions, and Dapr. I wanted to bring this to PHP and see if I could develop anything new. It’s mostly finished, and I’m currently bolting on new features before releasing the documentation.
Before that happens, I’d love to spend a few blog posts introducing Durable PHP. For those who have used Durable Functions before, this will seem immensely familiar, as it has a very similar API—though that is where the similarity ends.
There are three main components to any software written in Durable PHP:
- Activities,
- Orchestrations,
- and, Entities
Activities
Activities are very similar to “serverless functions” in that they have no state and no identity (technically, their result does have an identity, but we will get to that later), and they exist to cause side effects. In fact, Durable PHP uses activities to encapsulate and memoize side effects for use in Orchestrations.
Activities can be any code that you want to run exactly once in an Orchestration, such as sending emails to users, generating a random password, calling an external API, etc.
Orchestrations
Orchestrations are Event Sourced code that runs linearly, even if the underlying events are non-linear. Technically, the code is run multiple times until a point is reached where the result is not yet known (async on steroids). If that point is reached, the current state of execution is serialized until something changes that may indicate more code can be run. Then it is run again, and again, until it terminates.
For example, a “create project” Orchestration may send various components (through activities or sub-orchestrations) to create underlying infrastructure. These components may come up in various orders, but the code is still run linearly.
Further, external clients can subscribe to an execution’s state. This allows for providing reactive UIs instead of using “optimistic concurrency tricks” to hide the fact that something is asynchronous.
Entities
Entities are the core state and behavior holders of an application built on Durable PHP. Entities can run any code, but it is guaranteed to be synchronous. These are very similar to Akka actors, in that you can do whatever you want in them. But like Durable Functions, you can only do one thing at a time in a single instance.
Problems and Solutions
While building Durable PHP, I had to solve a number of problems and the great research literature out there helped out immensely. In a few cases, I had to work out things using the good ‘ole noggin, and I’d like to share how I approached those problems in some blog posts:
- Event Sourcing done “right”
- Cooperative distributed locking
- Authz and Ownership
- Retries and failures
- The arrow of time
- Time travel debugging; tests
-

The First Multi-Trillionaire
If there is one moment I’ll never forget, it was the little box hovering a few feet in the air. When my girlfriend walked in, she thought it was a clever piece of art, made to look as though held up by some wires hanging off the side. When I demonstrated that it really was just hovering there, she just walked out of the room saying “that’s cool.”
(more…) -
My Journey Home — Part 2
I moved around a lot as a kid; I always had to make new friends wherever I went. Our family was close, not because we necessarily liked each other, but because we didn’t have a choice. For a long while, home was with my family.
Then, one day, as a fresh 18-year-old, I stood outside my house in the pouring snow, watching my family through the window. I saw that they were happy and laughing, and they would be fine without me. It was at that moment that I realized this wasn’t my home.
My home was somewhere in the big wide world. I had to find it all myself.
I spent the next ten years traveling the world, building an ISP, fighting terrorism, and starting businesses. While I was moderately successful, I never found home.
Then, I moved onto a sailboat and met my wife.
Those were some of the hardest, most exciting, and life-filled days of my life up to that point. I had found my first real home since becoming an adult.
And if I ever thought that was hard, let me tell you about parenthood. Actually, let me skip a few years: we moved to the Netherlands.
I first came to the Netherlands in 2017 for work and immediately fell in love. Bikes were everywhere, people were actually walking around, and cafes had outdoor seating. It was awesome; that’s all I ever wanted out of a city: life.
It wasn’t until 2018 that we actually moved here and got a house in Utrecht. The adjustment was hard at first. You see, in America, everyone has this intense, I don’t know, paranoia? that pervades the entire culture, and when you don’t have to deal with it anymore… it can be hard sometimes.
But now. Now I have a sweet kitten sitting on my legs, a young man growing up faster than I can blink, a beautiful and amazing wife, and friends. I have a home. Home isn’t just the people that are a part of your life, the people that define you, push you to be better, and all that stuff. No, a home is made of that and the things you see every day … it’s στοργή, the natural affection we have for all the things around us. It’s a place we go to after a long day.
This post marks another reset, a fresh slate. This blog has been all over the place since 2005ish and it’s time to start over. Again.
Until next time,
Cpt. Rob
-
Golang is evil on shitty networks
This adventure starts with
git-lfs. It was a normal day and I added a 500 MB binary asset to my server templates. When I went to push it, I found it interesting thatgit-lfswas uploading at 50KB per second. Being that I had a bit of free time that I’d much rather be spending on something else than waiting FOREVER to upload a file, I decided to head upstairs and plug into the ethernet. I watched it instantly jump up to 2.5 MB per second. Still not very fast, but I was now intensely curious.Since I figured I would have originally been waiting FOREVER for this to upload, I decided to use that time and investigate what was going on. While I would expect wired ethernet to be a bit faster than wifi, I didn’t expect it to be orders (with an
s) of magnitude faster. Just to check my sanity, I ran a speed test and saw my upload speed on wifi at 40MB per second, and wired at 60MB per second.After some investigations with WireShark and other tools, I learned that my wifi channels have a shitload of interference in the 2Ghz band, and just a little in the 5Ghz band. During this time, I also learned that my router wouldn’t accept a single 5Ghz client due to a misconfiguration on my part. So, non-sequitur, apparently enabling “Target Wake Time” was very important (I have no idea what that does). Once that was fixed, I saw 600MB per second on my internal network and outside throughput was about the same as wired.
But, why on earth was
git-lfsso slow, even on 5Ghz? After looking at Wireshark while uploading togit-lfs, I noticed about 30-50% of the traffic was out-of-order/duplicate ACKs, causing retransmissions. I found that especially weird, not terribly weird because remember, this wifi network “sucks” with all my noisy neighbors. It turns out there are random 50-100ms delays all over the place. Probably due to interference. When I ran a speed test or browser session, however, it was less than 1%! In fact,git-lfswas barely sending any packets at all, like it was eternally stuck in TCP slow-start.
Graph showing packets-per-second (total) and packet errors for git-lfsWhen I looked at the packets, they were being sent in ~50-byte payload chunks (~100 bytes total, MTU is 1500). I found that very interesting because I would expect Nagle’s algorithm to coalesce packets so there would be fewer physical packets to send. That is when it hit me,
TCP_NODELAYmust be set.Between that, and extremely regular 100ms delays, it could only get off a few packets before getting a “lost packet,” not to mention nearly 50% of every packet was literally packet headers. I was literally, permanently stuck in TCP Slow Start.
TCP No Delay from Memory
Nagle’s Algorithm was written approximately 4 decades ago to solve the “tinygram” problem, where you are sending a whole bunch of little packets, flooding the network, and reducing network throughput. Nagle’s algorithm essentially bundles all the little packets into one big packet, waiting for an ACK or a full packet to be constructed, whichever is sooner.
Theoretically.
It’s a bit more complex than that due to decades of changes to make the web better and more performant… but turning on
TCP_NODELAYwould mean that each of those 50 bytes are sent out as one packet instead of just a few bigger packets. This increases the network load, and when there’s a probability that a packet will need to be retransmitted, you’ll see a lot more retransmissions.If you want to know more, use Google.
Diving in the code
From there, I went into the
git-lfscodebase. I didn’t see any calls tosetNoDelayand when I looked it up, it said it was the default. Sure enough:
Indeedly, the socket disables Nagle’s algorithm by default in Go.
Is this a trick?
I think this is a pretty nasty trick. The “default” in most languages I’ve used has
TCP_NODELAYturned off. Turning it on has some serious consequences (most of them bad).- Can easily saturate a network with packet overhead to send a single byte.
- Can send a whole bunch of small packets with high overhead (eg, half the data being sent is packet headers for
git-lfs) - Reduces latency (the only pro) by sending small packets
- Can cause havoc on an unreliable link
I wasn’t able to dig out why Go chose to disable Nagle’s algorithm, though I assume a decision was made at some point and discussed. But this is tricky because it is literally the exact opposite of what you’d expect coming from any other language.
Further, this “trick” has probably wasted hundreds of thousands of hours while transferring data over unreliable links (such as getting stuck in TCP slow start, saturating devices with “tinygram” packets, etc). As a developer, you expect the language to do “the best thing” it is able to do. In other words, I expect the network to be efficient. Literally decades of research, trial, and error have gone into making the network efficient.
I would absolutely love to discover the original code review for this and why this was chosen as a default. If the PRs from 2011 are any indication, it was probably to get unit tests to pass faster. If you know why this is the default, I’d love to hear about it!
That code was in turn a loose port of the dial function from Plan 9 from User Space, where I added TCP_NODELAY to new connections by default in 2004 [1], with the unhelpful commit message “various tweaks”. If I had known this code would eventually be of interest to so many people maybe I would have written a better commit message!
I do remember why, though. At the time, I was working on a variety of RPC-based systems that ran over TCP, and I couldn’t understand why they were so incredibly slow. The answer turned out to be TCP_NODELAY not being set. As John Nagle points out [2], the issue is really a bad interaction between delayed acks and Nagle’s algorithm, but the only option on the FreeBSD system I was using was TCP_NODELAY, so that was the answer. In another system I built around that time I ran an RPC protocol over ssh, and I had to patch ssh to set TCP_NODELAY, because at the time ssh only set it for sessions with ptys [3]. TCP_NODELAY being off is a terrible default for trying to do anything with more than one round trip.
When I wrote the Go implementation of net.Dial, which I expected to be used for RPC-based systems, it seemed like a no-brainer to set TCP_NODELAY by default. I have a vague memory of discussing it with Dave Presotto (our local networking expert, my officemate at the time, and the listed reviewer of that commit) which is why we ended up with SetNoDelay as an override from the very beginning. If it had been up to me, I probably would have left SetNoDelay out entirely.
rsc on Hacker NewsEffects elsewhere
This ‘default’ has some pretty significant knock-on-effects throughout the Go ecosystem. I was seeing terrible performance of Caddy, for example, on my network. It was fairly frustrating that I couldn’t identify the issue. But after some testing, now I know (I opened an issue).
Much (all?) of Kubernetes is written Go, and how has this default affected that? In this case, this ‘default’ is probably desired. Probably. The network is (usually) reliable and with 10G+ links between them, so they can handle sending small-byte packets with 40 byte headers. Probably.
This obviously affects
git-lfs, much to my annoyance. I hope they fix it… I opened an issue.When to use this?
In most cases,
TCP_NODELAYshouldn’t be enabled. Especially if you don’t know how reliable the network is and you aren’t managing your own buffers. If you’re literally streaming data a chunk at a time, at least fill a packet before sending it! Otherwise, turn offTCP_NODELAYand stream your little chunks to the socket and let Nagle’s Algorithm handle it for you.Most people turn to
TCP_NODELAYbecause of the “200ms” latency you might incur on a connection. Fun fact, this doesn’t come from Nagle’s algorithm, but from Delayed ACKs or Corking. Yet people turn off Nagle’s algorithm … :sigh:Here’s the thing though, would you rather your user wait 200ms, or 40s to download a few megabytes on an otherwise gigabit connection?
Follow along
This isn’t the end of the journey. Follow this blog to get updates.
-
Building the fastest PHP router ever
Ok, so the title might be a little bit click-baity since I haven’t compared it to every router in existence. Just nikic’s Fast Route.
On my sabbatical last summer, I was messing about with microservices (which I’m convinced are evil, but that is an article for another day). During that, I decided to create a dead-simple router. This router is based on the learnings you’ve maybe read here: how to abuse and use PHP arrays for speed. Go check it out if you haven’t already.
Anyway, I recently started on a project that I can’t wait to tell you all about, but alas, I used my dead-simple router. It wasn’t until I benchmarked it that I realized it was … um, faster than I thought.
+------+------------------+----------------------------------+-----+------+------------+-----------+--------------+----------------+ | iter | benchmark | subject | set | revs | mem_peak | time_avg | comp_z_value | comp_deviation | +------+------------------+----------------------------------+-----+------+------------+-----------+--------------+----------------+ | 0 | RouterBenchmarks | benchBuildingBlocksSimpleMatch | | 1000 | 1,155,328b | 1.804μs | +0.00σ | +0.00% | | 0 | RouterBenchmarks | benchBuildingBlocksWithVar | | 1000 | 1,156,360b | 2.655μs | +0.00σ | +0.00% | | 0 | RouterBenchmarks | benchBuildingBlocksHundredRoutes | | 1000 | 1,355,608b | 165.628μs | +0.00σ | +0.00% | | 0 | RouterBenchmarks | benchFastRouteHundredRoutes | | 1000 | 1,228,744b | 104.864μs | +0.00σ | +0.00% | | 0 | RouterBenchmarks | benchFastRouteWithVar | | 1000 | 1,181,736b | 5.153μs | +0.00σ | +0.00% | | 0 | RouterBenchmarks | benchFastRouteSimpleMatch | | 1000 | 1,177,960b | 2.193μs | +0.00σ | +0.00% | +------+------------------+----------------------------------+-----+------+------------+-----------+--------------+----------------+
And thus, I decided to share it with the world and tell you how it works.
Using the Router
Before you can initialize it, you have to install it.
composer require withinboredom/building-blocks
It’s part of my grab-bag “building blocks” repo that has some random stuff I’ve made. From there, it’s a pretty simple affair:
<?php $router = new Router($_SERVER['REQUEST_METHOD'], parse_url($_SERVER['REQUEST_URI'], PHP_URL_PATH)); $router->registerRoute( 'GET', '/hello/:name', static function (string $name): Result { return new Result(HttpResponseCode::Ok, "hello $name"); } ); $result = $router->doRouting(); $result->emit();And that’s it. Compared to FastRoute, it’s pretty darn simple. There are some downsides, but let’s see how it works first.
How it works
When you first initialize the router, we map over the array and normalize the requested URL. This basically just URL decodes the request and trims each path part. Thus
/my%20/////path===/my/path.We store that in an array:
['GET', ['my','path']]Then, when you register a route, we split the path again, so to register
/my/:idwe start with['my', ':id'].We then create an array based on the current request:
['my' => 'my', ':id' => 'path']and create a callback to generate the actual call to the handler and store it like['GET', ['my', 'path'], $callback]by replacing the current variable values with the state of the request.When we call
doRouting, we iterate over the generated handlers for an exact match, and the first one we find, we call the callback.The callback then takes the calculated parameters and passes them to the user-defined handler.
That’s literally it.
What about PSR compatibility?
I personally feel that PSR’s have resulted in bloat up and down the stack. Yes, they’re handy when composing packages, and even making this 100% PSR compatible is not at all complicated if you are so inclined.
Downsides
FastRoute can cache registered routes, while this algorithm cannot. In practice, this really only matters when you have hundreds of routes.
You’ll always get a
stringfor every path parameter.The first route to match will always win so you need to take some care in the order you register routes. Sure, the software can solve this, but this is an optimization the developer (or tooling) should be making, and not calculated during runtime.
Optimizations
I can optimize this router further, and I’d like to, eventually. There are a number of optimizations I’d like to make:
- 404’ing faster: Currently we have to check every … single … route for a possible match, including ones that make no sense. For example, there’s no reason to try testing a
GETrequest to aPOSTroute. - We calculate parameters twice. First to create the match, and second to call the route’s callback. Ideally, we’d only do this once.
- 404’ing faster: Currently we have to check every … single … route for a possible match, including ones that make no sense. For example, there’s no reason to try testing a
-
Algorithms in PHP: Deques (circular buffers & linked lists)
In the previous post, I talked about priority queues. But in my explanation of an alternative implementation, I neglected to mention a few things:
- The alternative implementation isn’t for production; there are edge cases and unhandled errors.
- The alternative implementation is meant for a short queue, not an infinite one, such as the one you may deal with in a single request.
- The performance of the alternative implementation may be misleading, in the worst case, it would perform far worse than the STL implementation. However, in my experience, priorities tend to bunch up vs. complete random priorities.
In this post, we’re going to go into Deques (pronounced “decks”), how they are usually implemented, and an alternative implementation that is specific to PHP. If you aren’t aware, PHP is getting a native Deque implementation in 8.2. A Deque is a double-ended queue that you can insert and remove from either end.
Deques are extremely powerful anytime you require a “queue of a bounded length” where the older items are dropped (like an undo buffer). However, this is one of those things where you really shouldn’t implement this in native PHP. STL Queues and Stacks can be used as a Deque and perform far better than anything you can implement in PHP. The reason for this should be evident if you’ve ever tried to prepend to an array; it is slow and gets slower the more items you add to the array.
A naive implementation
A naive PHP implementation of a Deque would probably look something like this:
<?php namespace Withinboredom\Algorithms\Deque; class Naive { private array $buffer = []; /** * Append to the end * * @param mixed $value * * @return void */ public function push(mixed $value): void { array_push($this->buffer, $value); } /** * Get from the end of the array * @return mixed */ public function pop(): mixed { return array_pop($this->buffer); } /** * Get from the beginning * @return mixed */ public function shift(): mixed { return array_shift($this->buffer); } /** * Append to the beginning * * @param mixed $value * * @return void */ public function unshift(mixed $value): void { array_unshift($this->buffer, $value); } }This naive implementation is so bad that I wouldn’t use it unless I dealt with less than a few dozen items. Here’s a chart of how bad it gets as the number of items gets larger:

Deques using circular buffers
Highly performant Deques use circular buffers to accomplish their goals, along with sophisticated logic to automatically grow and shrink the buffers to allow for an infinite number of items. You can imagine a circular buffer as being a clock-type structure. If you were to insert 12 items, it would look like a clock. For a Deque, we’d want two “pointers” to represent the “head” and the “tail” of our Deque, much like the hands on a clock.
We’ll imagine the hour hand to be our “head” and the minute hand to be our “tail” while discussing insertions and deletions. To prepend, we move the hour hand back and insert our new value. To append, we move the minute hand forward and insert our value. To remove from the head, we take the value from the hour hand and move it forward. To remove the tail, we take the value from the minute hand and move it backward.
We aren’t going to cover growing or shrinking circular buffers here to keep it simple.
So, let’s build our class:
<?php namespace Withinboredom\Algorithms\Deque; class CircularBuffer { private array $buffer = []; private int $head = -1; private int $tail = 0; public function __construct(private int $size) { } }First thing, we need a buffer to store items in, a head/tail pointer, and a max-size of the buffer. The reason for the strange head/tail initial values is to give us an easy way to tell whether we’re inserting an initial value or whether or not the buffer is full. Here’s how that works:
public function isFull(): bool { return ($this->head === 0 && $this->tail === $this->size - 1) || $this->head === $this->tail + 1; } public function isEmpty(): bool { return $this->head === -1; }Push
To push onto the buffer, we need to handle several states:
public function push(mixed $value): void { if ($this->isFull()) { throw new \Exception(); } if ($this->head === -1) { $this->head = 0; $this->tail = 0; } elseif ($this->tail === $this->size - 1) { $this->tail = 0;just a tiny } else { $this->tail += 1; } $this->buffer[$this->tail] = $value; }- our initial state
- wrapping around the circular buffer
- appending normally
Pop
To pop, we also need to handle several states:
public function pop(): mixed { if ($this->isEmpty()) { throw new \Exception(); } $return = $this->buffer[$this->tail]; if ($this->head === $this->tail) { $this->head -= 1; $this->tail -= 1; } elseif ($this->tail === 0) { $this->tail = $this->size - 1; } else { $this->tail -= 1; } return $return; }- when the buffer is full
- wrapping around the circular buffer
- popping normally
Shift and Unshift
Shifting and unshifting are handled the same, but in reverse:
public function shift(): mixed { if ($this->isEmpty()) { throw new \Exception(); } $return = $this->buffer[$this->head]; if ($this->head === $this->tail) { $this->head -= 1; $this->tail -= 1; } elseif ($this->head === $this->size - 1) { $this->head = 0; } else { $this->head += 1; } return $return; } public function unshift(mixed $value): void { if ($this->isFull()) { throw new \Exception(); } if ($this->head === -1) { $this->head = 0; $this->tail = 0; } elseif ($this->head === 0) { $this->head = $this->size - 1; } else { $this->head -= 1; } $this->buffer[$this->head] = $value; }The downside to this implementation is that a pre-determined size limits it, however, it is still pretty performant:

It’s a bit slower than the STL implementation (~86 vs. ~50 microseconds with a list size of 2,000). There are still several things to implement even to be close to being on par with the STL implementation:- ArrayAccess to access arbitrary elements
- Growing/shrinking the circular buffer
Linked Lists
Another potential possibility to traditionally implement a Deque is to use a doubly linked list. To accomplish that, we’ll need a “Node” class to represent each item in the list:
<?php namespace Withinboredom\Algorithms\Deque; class Node { public function __construct(public Node|null $previous, public Node|null $next, public mixed $value) { } }We can also add a few helpful behaviors:
setNext(),setPrevious(),resetNext(),resetPrevious(),removeMeNext()andremoveMePrevious().setNext()andsetPrevious()set the$next/$previousvariable and return$this:public function setNext(Node $next): Node { $this->next = $next; return $this; } public function setPrevious(Node $previous): Node { $this->previous = $previous; return $this; }resetNext()andresetPrevious()both unset next/previous:public function resetPrevious(): Node { $this->previous = null; return $this; } public function resetNext(): Node { $this->next = null; return $this; }removeMeNext()andremoveMePrevious()deletes itself from the chain and returns the next/previous Node:public function removeMeNext(): Node|null { $return = $this->next?->resetPrevious(); $this->resetNext(); return $return; } public function removeMePrevious(): Node|null { $return = $this->previous?->resetNext(); $this->resetPrevious(); return $return; }From there, the operations a pretty straightforward:
class LinkedList { public Node|null $head = null; public Node|null $tail = null; /** * Append to the tail * * @param mixed $value * @return void */ public function push(mixed $value): void { $this->tail = $this->tail?->setNext(new Node($this->tail, null, $value))->next ?? $this->head = new Node(null, null, $value); } /** * Get from the end of the array * * @return mixed */ public function pop(): mixed { $return = $this->tail?->value ?? throw new \Exception(); $this->tail = $this->tail->removeMePrevious(); return $return; } /** * Prepend * * @return mixed */ public function unshift(mixed $value): void { $this->head = $this->head?->setPrevious(new Node(null, $this->head, $value))->previous ?? $this->tail = new Node(null, $this, $value); } /** * Get from the beginning of the array * * @return mixed */ public function shift(): mixed { $return = $this->head?->value ?? throw new \Exception(); $this->head = $this->head->removeMeNext(); return $return; } }The performance is linear, just like before:

However, it still performs worse than a circular buffer or any STL implementation.
Php Specific implementation
If you’ve had to work extensively with PHP arrays, you’d probably guess why the naive implementation is so terrible. It’s not that bad, as long as you never unshift the array. Shifting/unshifting to a PHP array has terrible performance implications and should be avoided as much as possible. If you a bulk-prepending, it is usually faster to reverse the array, append your values, then flip the array again.
To avoid prepending to an array, we will use two arrays and only append to them. We’ll call these arrays “front” and “back”; appending to the “front” array is like prepending, and appending to the “back” array is just like regular appending. We pull from the end of each array to take from the “front” and “back,” respectively. Once the appropriate array is empty, we shift from the beginning of the other array until it is empty, which is still incredibly performant.
This implementation is really for when you need something custom, and the other types of algorithms wouldn’t work.
<?php namespace Withinboredom\Algorithms\Deque; class DoubleList { private array $front = []; private array $back = []; }To prepend, we append to
$front, and to append; we append to$back:public function unshift(mixed $value): void { $this->front[] = $value; } public function push(mixed $value): void { $this->back[] = $value; }When we pop, we check to see if
$backis empty; if it is, we take it from the start of $front. Otherwise, we take it from the back of$back:public function pop(): mixed { if (empty($this->back)) { // take the first item from the front and remove the item return array_shift($this->front); } return array_pop($this->back); }We similarly do the reverse for the shift:
public function shift(): mixed { if (empty($this->front)) { // take the first item from the back and remove the item return array_shift($this->back); } return array_pop($this->front); }This allows us to get around prepending by appending, almost as performant as the circular buffer implementation.

STL and when to use it
The STL implementations of Stacks and Queues can be used as Deque. Their performance (wall-clock time) will beat the crap out of these implementations; alternatively, if you are targeting PHP 8.2+, using the native Deque would be an even better solution — though we don’t know what that performance will look like yet.
For 99% of cases, you won’t need to implement your own Deque or any other basic algorithms. However, there are times when implementing your own can allow more business freedoms. For example, Beanstalkd implements its Priority Queue to do some things, such as removing items from the middle of the queue and adding a TTL for jobs. WordPress implements its Priority Queue (actions/filters) to support removal/insertion while iterating the queue and preventing infinite loops. Many other projects also end up embedding certain logic into these algorithms to support business logic in a performant way.
DS\Deque
There’s also the DS\Deque class, which is a proper Deque implementation; however, it requires being installed separately and does not come bundled with PHP. It is a little faster than using the STL libraries as a Deque. If you are looking for raw speed, this is the one you’re looking for.
When to use these algorithms
As I mentioned, sometimes you need to implement low-level algorithms to support high-performance business cases. It’s unlikely, but knowing how they work and some PHP-specific implementations can significantly impact when it matters.
-
Algorithms in PHP: Priority Queues (and Heaps)
This is the beginning of a series on implementing various algorithms in idiomatic PHP and their reference implementation (usually based on C++).
Today we’re going to be talking about Priority Queues. A priority queue is where each value has an associated “priority” that determines which order things come out of the queue. The best real-life priority queue would be an emergency room, where those patients with the most life-threatening issues are seen before the rest.
In most reference implementations, a priority queue is implemented using a Heap. A Heap is a binary tree-based structure that retains a specific value at the top of the tree. If the value is the max value of all the values, it is a “Max Heap,” and if it is the least, it is a “Min Heap.” Since we have a concept of “low priority” and “high priority,” we’ll consider a “Max Heap” here.
When you add an item to a Heap, you append it to the end of the Heap. If the newly appended value is lower than the parent, nothing needs to be done, else swap it with the parent and continue the check from that point. There are plenty of excellent articles on implementing a Heap, and we only need them to implement the “reference” implementation; for the idiomatic version of a priority queue, we don’t need a stinking Heap. 🙂
Interface
We’re only going to be implementing a few public functions:
<?php namespace Withinboredom\Algorithms\Heap; interface Heapish { public function insert(int $priority, mixed $value): void; public function removeMax(): mixed; public function getSize(): int; public function getMax(): mixed; }insertobviously inserts a new value with a given priority,removeMaxreturns the value with the highest priority and removes it from the queue, andgetMaxjust peeks at the highest priority value without removing it from the queue.The reference implementation
<?php namespace Withinboredom\Algorithms\Heap; /** * A basic priority heap implemented in C++-ish semantics */ class Reference { private int $heapSize = 0; private array $arr = []; public function __construct(public readonly int $maxSize) { } public function getMax(): mixed { return $this->arr[0]['value']; } public function getSize(): int { return $this->heapSize; } public function insert(int $key, mixed $value): void { if ($this->heapSize === $this->maxSize) { throw new \Exception("Heap is full"); } $i = $this->heapSize++; $this->arr[$i] = ['key' => $key, 'value' => $value]; while ($i !== 0 && $this->arr[$this->parent($i)]['key'] < $this->arr[$i]['key']) { $this->swap($i, $this->parent($i)); $i = $this->parent($i); } } private function parent(int $i): int { return (int)floor(($i - 1) / 2); } private function swap(int $first, int $second) { $temp = $this->arr[$first]; $this->arr[$first] = $this->arr[$second]; $this->arr[$second] = $temp; } public function deleteKey(int $i) { $this->increaseKey($i, PHP_INT_MAX); $this->removeMax(); } public function increaseKey(int $i, int $newKey) { $this->arr[$i]['key'] = $newKey; while ($i !== 0 && $this->arr[$this->parent($i)]['key'] < $this->arr[$i]['key']) { $this->swap($i, $this->parent($i)); $i = $this->parent($i); } } public function removeMax(): mixed { if ($this->heapSize <= 0) { throw new \Exception("Heap is empty"); } if ($this->heapSize === 1) { $this->heapSize--; return $this->arr[0]; } $root = $this->arr[0]; $this->arr[0] = $this->arr[--$this->heapSize]; $this->maxHeapify(0); return $root; } public function maxHeapify(int $i): void { $l = $this->leftChild($i); $r = $this->rightChild($i); $largest = $i; if ($l < $this->heapSize && $this->arr[$l]['key'] > $this->arr[$i]['key']) { $largest = $l; } if ($r < $this->heapSize && $this->arr[$r]['key'] > $this->arr[$largest]['key']) { $largest = $r; } if ($largest !== $i) { $this->swap($i, $largest); $this->maxHeapify($largest); } } private function leftChild(int $i): int { return 2 * $i + 1; } private function rightChild(int $i): int { return 2 * $i + 2; } }As you can see, the implementation is not very “php-ish” and does some pretty standard-ish things with arrays. However, this is based on an implementation in C++. In C++, arrays are very different than in PHP! In PHP, arrays can be sparse, sorted, or unsorted, and more importantly, we can access the underlying iteration mechanics to store state!
Looking over this implementation, you may notice a few other drawbacks. One, this implementation needs to be sorted on every insert, which incurs a
O(log n)cost, and is also incurred when removing the max item from the Heap. Let’s apply some PHP shenanigans to get it much faster…Utilizing the underlying cursor
The first optimization we can make is to utilize the array’s cursor and not sort on every insert. To do that, we need to keep track of whether or not an item has been inserted or not. So we’ll create a
$dirtyvariable, so we only need to sort right before we read from the queue. This will significantly simplify our inserts. Oh, since we don’t have to worry about array sizing, we can also toss out a potential exception:public function insert(int $key, mixed $value): void { $this->arr[$key][] = $value; $this->dirty = true; }Note that we append to an array with the value. This allows us to have multiple values with the same priority and retrieve them in the same order we insert them (FIFO — first in, first out), just like with a regular queue (our reference implementation does a FILO — first in, last out — implementation which doesn’t seem right to me).
Deletion can now be simplified as well:
public function deleteKey(int $i): void { unset($this->arr[$i]); }We don’t need to mark the array as dirty because it is already sorted or will be sorted when it is read. For simplicity, we aren’t concerned with multiple values here, and will likely be an application-level decision on how to handle that.
We also don’t need to keep track of the size of the queue anymore; we can just use the built-in function:
public function getSize(): int { return count($this->arr); }To get the max priority value, we first need to check if the queue is dirty. If it is dirty, we have to sort it. Then return the item:
public function getMax(): mixed { if ($this->dirty) { krsort($this->arr); $this->dirty = false; } $next = current($this->arr); return $next[0]; }It is very similar to removing the item from the queue as well; however, we have to rebuild the inner queue for a given priority if there is more than one item in the queue:
public function removeMax(): mixed { if ($this->getSize() === 0) { throw new \Exception("Heap is empty"); } if ($this->dirty) { krsort($this->arr); $this->dirty = false; } $current = key($this->arr); $return = current($this->arr); if (count($return) === 1) { unset($this->arr[$current]); return $return[0]; } $data = $return[0]; unset($return[0]); $this->arr[$current] = array_values($return); return $data; }You may be tempted to use an internal pointer for the little queues, but it will only save you a few microseconds unless you have very dense priorities (lots of values with the same priority).
public function removeMax(): mixed { if ($this->getSize() === 0) { throw new \Exception("Heap is empty"); } if ($this->dirty) { krsort($this->arr); $this->dirty = false; } $current = key($this->arr); $x = &$this->arr[$current]; $value = current($x); $next = next($x); if($next === false) { unset($this->arr[$current]); } return $value; }Here’s the complete listing:
<?php namespace Withinboredom\Algorithms\Heap; /** * An idiomatic PHP implementation of a heap. * * We are using a cursor here because we are utilizing the magic of sparse arrays! */ class Phpized { private array $arr = []; private bool $dirty = false; public function __construct() { } public function insert(int $key, mixed $value): void { $this->arr[$key][] = $value; $this->dirty = true; } public function deleteKey(int $i): void { unset($this->arr[$i]); } public function removeMax(): mixed { if ($this->getSize() === 0) { throw new \Exception("Heap is empty"); } if ($this->dirty) { krsort($this->arr); $this->dirty = false; } $current = key($this->arr); $x = &$this->arr[$current]; $value = current($x); $next = next($x); if($next === false) { unset($this->arr[$current]); } return $value; } public function getSize(): int { return count($this->arr); } public function getMax(): mixed { if ($this->dirty) { krsort($this->arr); $this->dirty = false; } $next = current($this->arr); return $next[0]; } }And a simple unit test:
<?php use Withinboredom\Algorithms\Heap\Phpized; it('inserts and removes items in the order they are inserted', function () { $heap = new Phpized(); for ($i = 0; $i < 1000; $i++) { $heap->insert(12, $i); } $heap->insert(15, 10); $heap->insert(0, 12); expect($heap->removeMax())->toBe(10); for ($i = 0; $i < 1000; $i++) { expect($heap->removeMax())->toBe($i); } expect($heap->removeMax())->toBe(12); expect($heap->getSize())->toBe(0); expect($heap->removeMax(...))->toThrow(\Exception::class); });Comparisons
I used PHP Bench to microbenchmark the two implementations alongside PHP’s SPL implementation. Naturally, the benchmarks are useless in their raw form but valuable for comparison to each other.
+----------------+-----------+----------+-----------+-----------+-----------+ | subject | mode | stdev | best | worst | mem_peak | +----------------+-----------+----------+-----------+-----------+-----------+ | benchReference | 998.044μs | 42.644μs | 950.360μs | 1.275ms | 931.560kb | | benchSpl | 301.795μs | 6.961μs | 294.900μs | 326.080μs | 574.280kb | | benchPhpized | 275.860μs | 7.220μs | 266.890μs | 302.150μs | 574.280kb | +----------------+-----------+----------+-----------+-----------+-----------+
What we can see is that this “phpized” implementation of a priority queue is faster than the C-based implementation or at least just as fast, even utilizing the same amount of memory. These implementations were run with the CLI opcache turned on, JIT enabled, and with dense priorities.
PHP can be faster than you expect
PHP arrays are downright powerful, allowing you to simplify some traditionally complex code, even totally abandoning traditional algorithms altogether in some instances (hint: there’s more to come!).
This is just the beginning of this series, and I hope you’ve found it as exciting and enlightening as I did building it! If you have any questions or suggestions, feel free to ask them in the comments!
-
Um, since when is PHP faster than C++?
Last week I was working on porting an encryption scheme to PHP from C++, mostly to embed it in a website and make changes to it specific to my use case; and for fun.
Needless to say, I was surprised to see my PHP version was faster than the C++ version. TL;DR: it isn’t faster, it was just computing the wrong thing.
The original
Here’s the original C++ code modified to isolate the slower bits:
#include <iostream> #include <cstdlib> #include <gmpxx.h> #include <sys/time.h> #define N 540 int main() { gmp_randclass* random = new gmp_randclass(gmp_randinit_default); random->seed(15); timespec start, finish; int i, j; mpz_class* p = new mpz_class[N]; mpz_class u, pt, x = 1; long nt = (unsigned) 1838 / 460; long np; clock_gettime(CLOCK_MONOTONIC, &start); #pragma omp parallel for private(pt, u, j) for (i = 0; i < N; i++) { p[i] = 1; for(j = 0; j < nt; j++) { if(j < (nt - 1)) np = 460; else np = 1838-460*(nt - 1); u = random->get_z_bits(np); mpz_nextprime(pt.get_mpz_t(), u.get_mpz_t()); #pragma omp critical { p[i] *= pt; } } x *= p[i]; } clock_gettime(CLOCK_MONOTONIC, &finish); std::cout << "Random x: " << mpz_get_str(NULL, 62, x.get_mpz_t()) << std::endl; std::cout << "Completed C++ random generation in " << (double)((finish.tv_nsec-start.tv_nsec)/1000000000.0+(finish.tv_sec-start.tv_sec)) << " seconds" << std::endl; }We are computing products of primes here, so nothing really fancy is going on. On my machine, it computes the products in almost exactly one second. Here’s the PHP port:
<?php const N = 540; function main(): void { $p = []; $x = gmp_init(1); $nt = abs(round(1838 / 460)); $start = microtime(true); gmp_random_seed(15); for ($i = 0; $i < N; $i++) { $p[$i] = gmp_init(1); for ($j = 0; $j < $nt; $j++) { if ($j < ($nt - 1)) { $np = 460; } else { $np = 1838 - 460 * ($nt - 1); } $u = gmp_random_bits($np); $pt = gmp_nextprime($u); $p[$i] *= $pt; } $x *= $p[$i]; } $finish = microtime(true); $time = $finish - $start; echo "Random x: " . gmp_strval($x, 62) . "\n"; echo "Completed PHP random generation in $time seconds\n"; } main();On my machine, it computes in 2.7 seconds, almost twice as slow. However, the C++ version is using some parallelization magic that I’m not going to implement in PHP. To do so would require spawning some threads and communicating with them via queues or pipes using System V or pipes, respectively. I don’t really feel like building that or vetting a library that does it for me, so we’ll just remove the parallelization from the C++ bits. It now looks like this:
#include <iostream> #include <cstdlib> #include <gmpxx.h> #include <sys/time.h> #define N 540 int main() { gmp_randclass* random = new gmp_randclass(gmp_randinit_default); random->seed(15); timespec start, finish; int i, j; mpz_class* p = new mpz_class[N]; mpz_class u, pt, x = 1; long nt = (unsigned) 1838 / 460; long np; clock_gettime(CLOCK_MONOTONIC, &start); for (i = 0; i < N; i++) { p[i] = 1; for(j = 0; j < nt; j++) { if(j < (nt - 1)) np = 460; else np = 1838-460*(nt - 1); u = random->get_z_bits(np); mpz_nextprime(pt.get_mpz_t(), u.get_mpz_t()); { p[i] *= pt; } } x *= p[i]; } clock_gettime(CLOCK_MONOTONIC, &finish); std::cout << "Random x: " << mpz_get_str(NULL, 62, x.get_mpz_t()) << std::endl; std::cout << "Completed C++ random generation in " << (double)((finish.tv_nsec-start.tv_nsec)/1000000000.0+(finish.tv_sec-start.tv_sec)) << " seconds" << std::endl; }It now completes in about 8.2 seconds, compiling with
-O3. That’s far slower than the PHP version… but why? What is going on?Identifying the differences
In the C++ version, there are several operations that could be slower than in the PHP version:
- multiplication of gmp values
- calculating random numbers
- calculating the next prime number
I calculated the total time spent on each of these operations in C++ vs. PHP:
Operation PHP (secs) C++ (secs) Multiplication 0.058 0.058 Random bits 0.0012 0.0001 Next Prime 2.65 8.24 OK, so now to the gmp extension source code to understand how it is calculating primes so quickly. Maybe there’s something we can learn?
Here’s the function in question: on Github.
/* {{{ Finds next prime of a */ ZEND_FUNCTION(gmp_nextprime) { gmp_unary_op(mpz_nextprime); } /* }}} */These are using the exact same functions under the hood, however, we’re still manually unwrapping to the c-type in our function (
.get_mpz_t()), maybe that is the culprit?It turns out that is not the culprit at all, it’s the calculation of the next prime number after all. At this point, the only thing I can think of is the quality of the primes. Perhaps the C++ version is calculating better primes that are bigger? Or something.
Since we are asking for random numbers containing at least X random bits, let’s calculate the average number of bits actually returned.
Language Number bits C++ 611 PHP 458 Aha! The culprit! It is indeedly the quality of the primes. After some further investigation, it looks like it boils down to this calculation:
1838 / 460Fixing the bug
Well, it turns out there was a subtle bug. The C++ version casts this to unsigned (these are variables in the actual code):
1838 / 460, and in the PHP version we do:abs(round(1838 / 460))which is not the same. We want the floor (in PHP, it will magically cast to a float when doing integer division, so we need to do the truncation manually):abs(floor(1838 / 460)).This results in the PHP version taking 8.4 seconds and generating the appropriate number of random bits, just a tad bit slower than the C++ version and they generate the exact same product as well (since they have the same random seed).
Some key takeaways
I’m only doing this for fun and to satisfy my own curiosity while on my three-month sabbatical. I don’t recommend porting cryptographic functions from C/C++ to PHP unless you really know what the hell you’re doing. PHP has no concept of “unsigned long” and cryptographic algorithms generally rely on them quite heavily. PHP’s maximum integer is
9223372036854775807and C++’s maximum unsigned long is18446744073709551615on my machine. This can create serious issues if you need bigger numbers, or serious performance implications if you try to emulate them. Instead, use PHP’s FFI extension to call into the C/C++ code as a library.But when PHP appears to be faster than C++, you have a bug! Finding that bug might not be obvious, it might be subtle, like this one.
-
A More In-Depth Reasoning behind PHP as a good language
Yesterday, I wrote a post over lunch that people just absolutely hated. It was great, in sort of weird way, to see that many people didn’t see what I saw when I posted it. I think it was a somewhat-not-gentle reminder that I see the world differently.
The post was shared on Reddit and I personally shared it on Hacker News (which was flagged) just for giggles to see if there would be any interesting conversations. Indeedly, I got some “interesting” comments:
But wow, this is not a convincing article at all. It’s just an opinion with nothing to back it.
wccrawford on https://news.ycombinator.com/item?id=30700298No substantive argument made here, except “PHP has changed in the past 10 years”.
krageon on https://news.ycombinator.com/item?id=30698957When you’re this wrong about a topic, most people quit even trying to correct you.
spacemanmatt on https://news.ycombinator.com/item?id=30699677There were similar things on Reddit. Truthfully, I didn’t expect people to see what I saw when I posted that post. However, I think it is probably worth digging a little deeper into the post, just to help anyone out who comes along later.
Like, look at this Merge Sort in C# (130 lines) and then look at it in PHP (31 lines). You can’t beat that kind of productivity, not to mention in PHP, you can even mix data types (like ints and floats) where in the C# version, it’d be much more difficult.
https://withinboredom.info/blog/2022/03/16/my-favorite-language-has-changed-to-php/People took this to mean that LOC is what makes them productive(?). I totally get why people would think that because I didn’t spell it out. We learn algorithms like Merge Sort because we should never implement them ourselves. So, why do we learn something we shouldn’t use? Why do we test for it in interviews? The answer is obvious to me, but again, I see the world differently than most.
Think about it, “we should never implement them” which means you need to be able to recognize when you are, or code you’re reviewing is accidentally implementing them, which means you need to know what they look like so you can point it out.
PHP is a ridiculously concise language for being C-like, probably due to the huge amount of built-in functionality, where C# is much more verbose. You can spot the merge sort in PHP at a basic glance, where you have to tease apart the C# version to figure out it is a merge sort. That was my point, not that LOC is important to productivity, but the fact that PHP is so concise, that you can spot common algorithms from a mile away.
However, there are cases for custom implementations, as long as you know what you’re doing. WordPress and Beanstalkd both implement custom priority queues, and they’re faster than they should be because of it. Does that make it harder to maintain and change those pieces? You bet! But sometimes being fast is better than being easy to maintain — such as on critical paths.
So, how does this tie into productivity? If you can easily spot common algorithms/patterns, you have a wealth of information at your fingertips to help you optimize the code, make it easier to understand, and deliver more value to the end-user. If common algorithms are obfuscated, you’ll miss the forest for the trees and not realize the wealth of information you could have had.
When I learned Assembly, I think I broke my brain, permanently. New paradigms were learned, old ways to do things were suddenly way too long. I don’t really know how to explain it, but when I came back to C#, suddenly, I felt too constrained.
https://withinboredom.info/blog/2022/03/16/my-favorite-language-has-changed-to-php/I was optimizing a bluetooth door lock I made myself for my front door. I basically had a very small amount of memory. It was tremendously fun, to figure out how to do everything I wanted to do and squeeze it into a very small amount of flash memory. I think we’d call it spaghetti code if it were written in a higher-level language. 🙂
Writing spaghetti on-purpose is truly harder than writing good code, and optimizing spaghetti is even harder. I highly recommend it, it’s similar to the paradigm shift required to learn languages like Haskell when all you know is procedural/OOP style code.
Anyway, lunchtime is over and I think I covered the big things I wanted to address. Enjoy your day!
-
Yes, PHP is faster than C#
So, I got an interesting spam comment on my post today:
“It gets even crazier when you actually benchmark the two languages only to discover in some real-world cases, PHP outperforms C#.”
I triple dare you to show code examples so we can explain why you’re wrong.
Quadruple dare
Jesus christ, how did you think this was true
By: No McNoingtonThis person couldn’t even be bothered to put in a decent pseudonym to call them by, but Mr./Mrs. McNoington, prepare to be blown away…
See, there’s something very common that all developers must do, and that is read files… we need to parse things, transform file formats, or whatever. So, let’s compare the two languages.
function test() { $file = fopen("/file/file.bin", 'r'); $counter = 0; $timer = microtime(true); while ( ! feof($file)) { $buffer = fgets($file, 4096); $counter += substr_count($buffer, '1'); } $timer = microtime(true) - $timer; fclose($file); printf("counted %s 1s in %s milliseconds\n", number_format($counter), number_format($timer * 1000, 4)); } test();using System.Diagnostics; using System.Text; var test = () => { using var file = File.OpenText("/file/file.bin"); var counter = 0; var sw = Stopwatch.StartNew(); while(!file.EndOfStream) { if(file.Read() == '1') { counter++; } } sw.Stop(); Console.WriteLine($"Counted {counter:N0} 1s in {sw.Elapsed.TotalMilliseconds:N4} milliseconds"); }; test();Personally, I feel like this is a pretty fair assessment of each language. We will synchronously read a 4Mib file, byte-by-byte, and count the 1’s in the file. There’s very little user-land code going on here, so we’re just trying to test the very fundamentals of a language: reading a file. We’re only adding the counting here to prevent clever optimizing compilers (opcache in PHP, release mode in C#) from cheating and removing the code.
“But Rob,” I hear you say, “they’re not reading it byte-by-byte in the PHP version!” and I’d reply with, “but we’re not reading it byte-by-byte in the C# version either!”
Let’s see how it goes:
PHP: 32.49 ms (avg over 10 runs) C#: 37.30 ms (avg over 10 runs) That’s pretty crazy… I mean, we just read four megs, which is about the size of a decent photo. What about something like a video clip that might be 2.5 gigs?
PHP: 24.82 s (avg over 10 runs) C#: 26.67 s (avg over 10 runs) Now, I need to process quite a bit of incoming files from banks and bills and stuff for my household budgeting system, which is how I discovered this earlier last year as I was porting things over from a hodgepodge of random stuff to Dapr and Kubernetes. PHP is actually faster than C# at reading files, who knew?!
Does this mean you should drop everything and just rewrite all your file writing stuff in PHP (or better, C)? no. Not at all. A few milliseconds isn’t going to destroy your day, but if your bottleneck is i/o, maybe it’s worth considering :trollface:?
Nah, don’t kid yourself. But if you’re already a PHP dev, now you know that PHP is faster than C#, at least when it comes to reading files…
Feel free to peruse some experiments here (or if you want to inspect the configuration): withinboredom/racer: racing languages (github.com)
Can this C# be written to be faster, sure! Do libraries implement “the faster way?” Not usually.
Addendum
Many people have pointed out that the C# version isn’t reading it in binary mode and the function call overhead are to blame. Really? C# is many order of magnitudes faster than PHP at function calls. I promise you that isn’t the problem. Here’s the code for binary mode on the 2.5gb file:
using System.Diagnostics; using System.Text; var binTest = () => { using var file = File.OpenRead("/file/file.bin"); var counter = 0; var buffer = new byte[4096]; var numRead = 0; var sw = Stopwatch.StartNew(); while ((numRead = file.Read(buffer, 0, buffer.Length)) != 0) { counter += buffer.Take(numRead).Count((x) => x == '1'); } sw.Stop(); Console.WriteLine($"Counted {counter:N} 1s in {sw.Elapsed.TotalMilliseconds} milliseconds"); }; binTest();If you now want to complain that it’s all Linq’s fault, we can just remove the
.Takeand double count things because I need to get to work and I’m not putting any more time to telling people the sky is blue.with .Take: 38.40s (2.5gb file)without .Take: 23.5s (2.5gb file — but incorrect implementation)So yeah, if an incorrect implementation is the proof you need that PHP is slower, go for it. Time to go to work.
Addendum 2
Since people come here wanting to optimize the C# without optimizing the PHP version, here is an implementation ONLY looking at file performance:
function test() { $file = fopen("/file/file.bin", 'r'); $counter = 0; $timer = microtime(true); while (stream_get_line($file, 4096) !== false) { ++$counter; } $timer = microtime(true) - $timer; fclose($file); printf("counted %s 1s in %s milliseconds\n", number_format($counter), number_format($timer * 1000, 4)); } test();var binTest = () => { using var file = File.OpenRead("/file/file.bin"); var counter = 0; var buffer = new byte[4096]; var sw = Stopwatch.StartNew(); while (file.Read(buffer, 0, buffer.Length) != 0) { counter += 1; } sw.Stop(); Console.WriteLine($"Counted {counter:N} 1s in {sw.Elapsed.TotalMilliseconds} milliseconds"); }; binTest();And here are the results:
PHP: 423.50 ms (avg over 10 runs) C#: 530.42 ms (avg over 10 runs) -
My Favorite Language has Changed to PHP
For the last 15 years or so, my favorite language has been C#, despite using mostly PHP in my workplace since 2012. Over the years, I’ve written a lot of side-projects in C#, and it’s been great, for the most part. Until I learned Assembly… last year.
When I learned Assembly, I think I broke my brain, permanently. New paradigms were learned, old ways to do things were suddenly way too long. I don’t really know how to explain it, but when I came back to C#, suddenly, I felt too constrained.
Like, look at this Merge Sort in C# (130 lines) and then look at it in PHP (31 lines). You can’t beat that kind of productivity, not to mention in PHP, you can even mix data types (like ints and floats) where in the C# version, it’d be much more difficult.
It gets even crazier when you actually benchmark the two languages only to discover in some real-world cases, PHP outperforms C#. Yeah, I know outlandish claims requires substantial proof, but I’m not here to prove to it you. I’m just talking about my reasons for PHP becoming my favorite language (and yes, writing multithreaded PHP is still a PITA).
There are some things I don’t like about PHP, like, the fact that you need two separate processes to serve web pages at scale (nginx + php-fpm). Some of that is solved with Swoole/ReactPHP/AmpPHP and friends, but then you end up needing to rewrite things to work, using special database drivers and things. I’m hoping with PHP Fibers, that’ll be a thing of the past, eventually.
Although, if you’re running something like the nginx ingress in Kubernetes, you can just use the Fastcgi target directly, without an intermediary. That’s actually pretty nice. In this environment, I think it’s actually better than running a native web-server on the pod. There’s no need to parse a forwarded HTTP request (or do http2 to http1 translations), since you’re actually operating on the original HTTP request. Maybe it would be nice if C# provided a Fastcgi binding…
Anyway, I just wanted to announce this to the world because PHP has a bad rap pre-5.3. Since PHP 5.6, things have changed quite a bit. If you haven’t used PHP in the last 7-8 years, you should give it a go.
-

The Growth of a Programmer
Writing software is hard. I’m reminded of that every time someone asks me to teach them. The basics are convoluted, the syntax is unique; It’s 100% logic that you have to hold in your head while you craft words that semantically make little sense, unless you’re a compiler or interpreter. (more…)
-
My Journey Home
It has been a little over a year since I got the boat. As you may have heard, it has been quite the adventure. (more…)